Petroleum engineering runs on information in the form of data. However, engineers need to spend too much time searching for data, especially unstructured data found in documents. Examples include almost all of the information in the SPE and company repositories in the form of Microsoft Word, PowerPoint, and Excel documents, pdfs, web pages, tables, images, videos, audio files, newsfeeds, tweets, and email messages. The lack of structure makes unstructured data hard to find and analyze without extensive semantic tagging, which is traditionally performed by humans. This process is in contrast to the relative ease with which structured data in traditional databases can be found and analyzed (Taylor, 2018).
Data professionals—the people who focus on finding and analyzing data—report spending 14 hours a week looking for data, and another 10 hours re-creating data that cannot be found. That means half the week is spent just trying to get the data they need to do the required analysis (idm, 2018).
The SPE Research Portal
Over the past 5 years, SPE and i2k Connect have developed the SPE Research Portal to address the challenges facing engineers who are looking for information. The collection currently contains approximately 255,000 distinct items, with content doubling every 10 to11 years. The portal has been described in earlier publications (Schoen et al., 2018 and Boden and Smith, 2019), and is available on the SPE.org homepage and SPE mobile app.
Four Examples of Searches on the SPE Research Portal
1. Find OnePetro Articles About “Digital Oilfield” That Focus on Artificial Lift Systems

This example is analogous to online shopping. The user starts with the search phrase “digital oilfield” (as of this writing, there are 811 results), and then refines the search by clicking on OnePetro (for 637 results). Next, the user further narrows the results by clicking on “Artificial Lift Systems,” a class in the SPE Disciplines taxonomy. This reduces the set to 57 results, a more manageable number. Each individual result has an information card that shows the different enrichments computed by the portal’s artificial intelligence technology.
The information card for each search result shows four or five tabs: quick summary, highlights (similar to an Internet search engine snippet), topics (classifications in the taxonomies), concept tags (important words or phrases), and publishing (SPE paper number, etc.). Clicking on the “i” button above the information card brings up a new page with more detailed information.
Faceted search, through the filters, complements literal search terms using tags and metadata automatically added by the system. In this example, the class “Artificial Lift Systems” is one of the 400-plus classes in the SPE Disciplines taxonomy. This class represents about 1,000 text clues known to the portal, including all the different types of artificial lift systems (e.g., electric submersible pumps, gas lift).
Each page of results includes a four-panel dashboard (timeline, word cloud, world map, and collaborating authors network). These panels enable the user to further narrow the results or explore distributions and trends across the set of results.
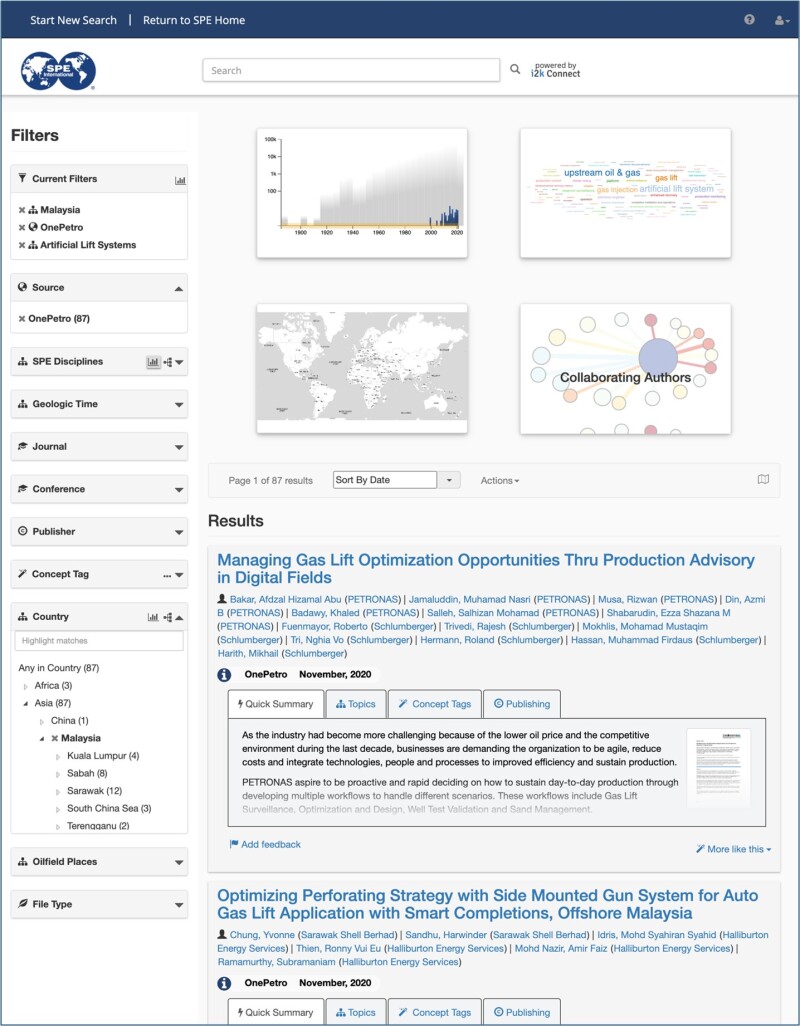
2. Find OnePetro Articles on Artificial Lift Systems in Malaysia
This example does not involve any specific search terms. It relies on faceted search, enabled by auto-classification into the SPE Disciplines and Country taxonomies. The results are shown in Fig. 2.
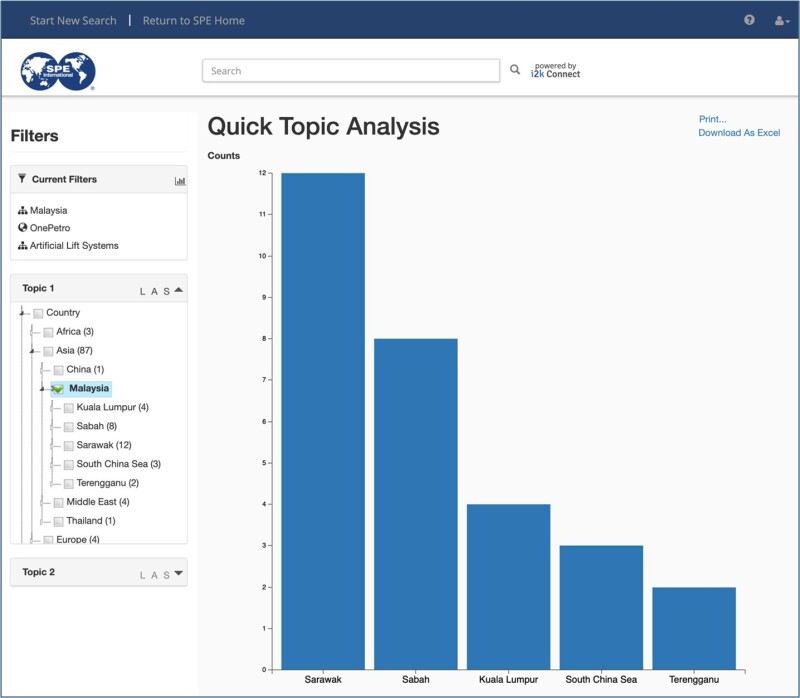
3. Show the Distribution of OnePetro Articles on Artificial Lift Systems in Malaysia
A Quick Topic Analysis can be done by clicking on the small graph icon to the right of the Current Filters tab. This example shows how analysis of distributions and trends is enabled by the structured metadata automatically added to the content. The results are shown in Fig. 3.
The portal recognizes the names and attributes of both geographical and petroleum basin information such as country, state, county, field, basin, formation, and well across the world. Industry professionals can drill down to field or formation information and then display it on a map, or find graphical aspects of the files to show correlations. The dynamic visualization tools enable users to quickly relate one feature to another across multiple documents.
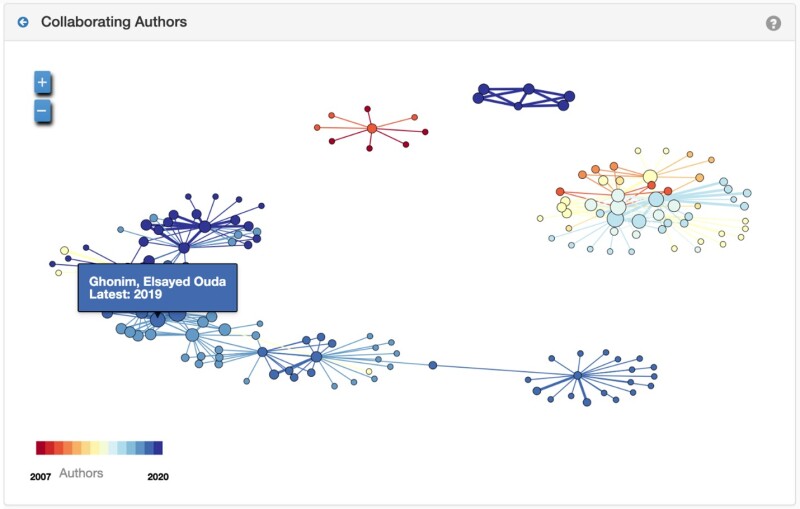
4. Show a Social Network Analysis of OnePetro Articles on Artificial Lift Systems in Malaysia
Knowledge management can be described as having two major thrusts: Connecting people to information and connecting people to people. Thus far, the examples have demonstrated the people-to-information connection. This example demonstrates the people-to-people connection, which can be viewed by clicking on the Collaborating Authors panel. This information helps identify the experts who may be contacted with questions.
The larger the circle, the more articles written by that author. The links indicate co-authorship. Slide over the circles to see author names and click to see articles they wrote. It is clear that most of the authors are with Petronas, and several papers were co-authored with people from service companies. Click below the color key on “Authors” to toggle between authors and institutions.
The i2k Connect AI Platform
The SPE Research Portal is implemented on the i2k Connect AI platform that integrates subject matter expertise with Al natural language processing (NLP) and machine learning (ML). The name “i2k Connect” is intended to embody the idea of connecting information in documents to knowledge that can be used for decision-making and action. The platform automatically enriches documents by classifying them into relevant taxonomies, geotagging oil fields, and extracting key concepts, authors, institutions, titles, and summaries.
Not only do these AI-powered enrichments assist people in finding and analyzing information, they also free up time for SPE staff members who must otherwise manually tag documents.
The SPE Research Portal classifies documents into four of the 15 taxonomies in the i2k knowledge base: SPE disciplines, geologic time, country (regions, countries, states, counties, etc.), and oil field places (petrogeography such as basins, fields, formations, wells, etc.).
The components of the i2k AI platform and the services it delivers are shown in Fig. 5.
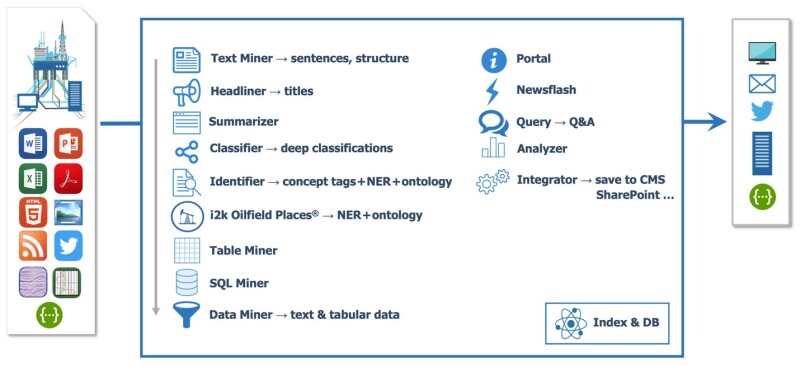
On the left side are some of the sources that the platform can process; on the right are ways in which users and systems can interact with the platform. In the middle are the processing pipeline and components.
In the preceding section we focused on human interaction examples. But systems like Schlumberger’s DELFI Cognitive E&P Environment use application programming interfaces to interact with the platform.
Domain knowledge. One of the earliest learnings in applied AI is “in the knowledge lies the power.” To this end, the i2k AI platform has millions of pieces of information and knowledge built in, e.g., information on the names, locations, and other relevant parameters of 100,000 basins, fields, wells, and formations; over a million relevant natural-language terms and their mappings into 15 taxonomies; natural-language knowledge such as parts of speech and what constitutes a good keyword phrase (called a “concept tag” in the SPE Research Portal); knowledge of how to recognize and interpret tabular data in pdf and other file formats; and knowledge of how to extract data points from sentences. Going forward, i2k Connect will continue to broaden, extend, and deepen the knowledge in the platform.
Deployment. It is worth noting that much of the effort in delivering the AI in any commercial system is devoted to non-AI issues like integration into the existing corporate infrastructure, information security architecture, and workflows to provide useful products and services. Consider processing speed, to which we devote a great deal of attention, because company repositories frequently contain tens of millions of documents.
Additional capabilities are needed for knowledge management applications beyond those already visible in the present SPE Research Portal. The i2K Platform contains additional features such document libraries, a well file dashboard, drilling events, structured data in tables and databases, additional knowledge bases, alerts, search on ambiguous place names, duplicates, mergers, acquisitions, and divestitures. A new AI capability to be delivered this year is a chatbot that understands oil and gas.
In the longer term, addressing the industry’s demanding knowledge management requirements will require deeper understanding of the content of documents. This has been a major area of research in AI for decades, with substantial progress in recent years. Our strategy is to maintain close contact with the latest research through our work with the Association for the Advancement of Artificial Intelligence (AAAI), and then integrate what can be delivered robustly into the SPE Research Portal and other customer deployments. (AITopics.org was created by AAAI and is powered by i2k Connect. It is the Internet’s largest collection of information on research, people, news, and applications of AI.)
How Can Young Professionals Contribute?
For young professionals, there are many opportunities to share knowledge, insights, experience, and energy on any or all present or future knowledge management capabilities. They can get involved today by using the SPE Research Portal and offering feedback—pointing out errors and making suggestions for new capabilities. They can test those capabilities as they appear and suggest questions that might be answered in the SPE corpus. They can also get involved in the evolution of the SPE Technical Disciplines taxonomy.
Human guidance can focus learning for faster improvement. There is value in sharing cases in which programs have not found a good answer, more so than examples that reinforce what it already knows. Examples of deficiencies are particularly valuable when a correct answer can be supplied. When an incorrect answer is close to a good one, a so-called “near miss,” feedback helps the program make finer distinctions. Thus, it is particularly helpful when users challenge it with hard cases that require fine distinctions and provide correct answers for the near misses. When learning programs depend on statistics alone, they require many more training examples. Similarly, questions that the system cannot yet answer also help focus learning and improvement.
For those looking for a career in applied AI, data science, or engineering analytics, there are numerous problems to be solved before we can extract and analyze data in unstructured documents as easily as with structured data in databases and applications.
There are many other cases where today’s academic research is not ready for routine use in the energy industry. Some involve the long-tail—edge cases that must be solved to achieve very high accuracy. Professionals with a combination of petroleum engineering and AI knowledge are well placed to address these problems in the way ahead.
Acknowledgments
Thanks to the i2k Connect team and John Boden and his colleagues at SPE. Thanks also to the SPE directors who have provided support, feedback, and encouragement. This work has been supported in part by the National Science Foundation Small Business Innovation Research Program, Award #1415757 and #1534798.
Bibliography
Boden, J. S. and Smith, R. G. Powering Knowledge Discovery and Knowledge Flow with AI. Presented at APQC's 2019 Knowledge Management Conference, Houston, TX, USA, 3 May 2019.
Buchanan, B. G., Davis, R., Smith, R. G., and Feigenbaum, E. A. 2018. Expert Systems: A View from Computer Science. In The Cambridge Handbook of Expertise and Expert Performance (Cambridge Handbooks in Psychology), ed. K. Ericsson, R. Hoffman, A. Kozbelt, and A. Williams, 84–104. Cambridge, UK: Cambridge University Press.
Chui, M., Manyika, J., Bughin, J., Dobbs, R., Roxburgh, C., Sarrazin, H., Sands, G., and Westergren, M. 2012. The Social Economy: Unlocking Value and Productivity Through Social Technologies. McKinsey Global Institute.
Idm. 2018. Data Professionals Waste Half their Time: Survey.
Devlin, J., Chang, M-W, Lee, K., and Toutanova, K. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol. 1 (Long and Short Papers), Association for Computational Linguistics, Minneapolis, Minnesota, USA.
Duthie, L., Arukhe, J.O., and Namlah, S. 2015. The Evolution of Well-Testing Practices From Conventional to Zero Flaring in a Saudi Aramco Oilfield Development. Paper presented at the SPE Middle East Oil & Gas Show and Conference.
Eckroth, J., & Schoen, E. (2019). A Genetic Algorithm for Finding a Small and Diverse Set of Recent News Stories on a Given Subject: How We Generate AAAI’s AI-Alert. Proceedings of the AAAI Conference on Artificial Intelligence, 33 (01), 9357–9364.
Herzig, J., Nowak, P.K., Müller, T., Piccinno, F. and Eisenschlos, J.M. TAPAS: Weakly Supervised Table Parsing via Pre-Training. arXiv preprint arXiv: 2004.02349, 2020.
Rajpurkar, P., Zhang, J., Lopyrev, K., and Liang, P. SQuAD: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250, 2016.
Ray, T. 2021. ‘Weird new things are happening in software,’ says Stanford AI professor Chris Re. ZDNet.
Schoen, E. J., Smith, R. G., and Boden, J. S. 2018. AI Supports Information Discovery and Analysis in an SPE Research Portal. SPE-191758-MS. Presented at the SPE Annual Technical Conference and Exhibition, Dallas, TX, USA.
Smith, R. G. and Eckroth, J. 2017. Building AI Applications: Yesterday, Today, and Tomorrow. AI Magazine 38 (1): 6–22.
Taylor, C., 2018. Structured vs. Unstructured Data. Datamation.
Transformers, 2021. https://huggingface.co/transformers/.
The authors are members of the i2k Connect team: Reid G. Smith, cofounder and CEO; Eric J. Schoen, CTO; Joshua R. Eckroth, chief architect; David Mack Endres, technical advisor; Sebastian Florez, software developer; Julia Rasmussen Elliott, director of service delivery; and Bruce G. Buchanan, cofounder and chief scientist. They have many years of oil and gas experience at Schlumberger, Marathon Oil, and Noble Energy. Four members of the team hold PhDs in artificial intelligence and two are Fellows of the Association for the Advancement of Artificial Intelligence.
[The article was sourced from the authors by TWA editor Jaspreet Singh.]