

A recently published promising article showcases the application of a novel machine learning (ML) solution to a familiar operational challenge. Encouraged by the reported accuracy and clean results, you attempt to apply the methodology in your own field. Very quickly, however, reality sets in: The training assumptions bear little resemblance to operational conditions. The data are noisy, the system is nonstationary, and key boundary conditions simply do not exist in practice.
This scenario plays out across our industry with notable frequency. While ML publications in oil and gas have grown at 15% annually over the past decade, yielding over 11,000 articles, only 15% of organizations have successfully moved artificial-intelligence projects beyond the research and pilot stage into live operations (Póvoas et al. 2025). The bottleneck is rarely from the absence of sophisticated algorithms. Instead, it comes from a persistent misalignment between research practices and industrial realities, between what demonstrates feasibility in a controlled study and what engineers can reliably use in day-to-day operations.
Before exploring why this gap persists, it is useful to distinguish three stages commonly observed in ML development. The first consists of proof-of-concept studies and academic prototypes, where models are tested on curated data sets. The second includes pilot deployments, often limited to specific assets or short time windows. The third and least common stage consists of fully embedded solutions, models that are integrated into workflows, maintained over time, and trusted by engineers and management alike. Most ML efforts in oil and gas never progress beyond the first two stages. This is where innovation quietly stalls.
Why ML-Based Research Often Fails To Deploy
Four recurring gaps consistently emerge when translating ML research into industrial deployment (Fig. 1).
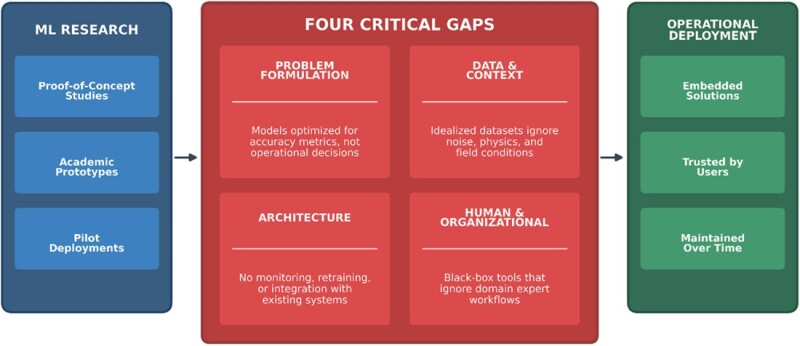
Problem Formulation Gap. Many studies are framed around algorithmically interesting problems rather than decision-driven ones. Maximizing an accuracy metric on historical production data may produce an elegant result, but it does not necessarily help a production engineer decide how to adjust a choke setting or rank infill well candidates. When research optimizes models instead of decisions, it often delivers insight without impact.
Data and Context Gap. Academic models frequently rely on idealized data sets that do not reflect field conditions. In practice, oil and gas data are sparse, biased, interrupted by unplanned/unexpected operational events, and shaped by physics. Models trained on steady-state assumptions struggle when faced with workovers, shut-ins, sensor drifts, or changing operating policies. Without embedding domain context and physical constraints, even highly accurate models can fail catastrophically in production.
Architecture Gap. A working Python or MATLAB notebook is not a deployable system. Many research efforts stop once a model performs well offline, without addressing how it will be monitored, retrained, or integrated into existing platforms. Model drift, data quality degradation, and changing operational regimes are realities even for technology companies with mature or advanced ML infrastructure (Zaman 2025). In the oil and gas industry, where systems are more complex and feedback loops slower, ignoring life-cycle considerations almost guarantees failure.
Human and Organizational Gap. Perhaps most critically, research often neglects end-user workflows and interpretability requirements. The “acceptance gap between traditional operations and ML tools” (Bhadauria 2025) isn’t really about resistance to change; it’s largely about tools that don’t fit how domain experts—reservoir engineers, drilling supervisors, and production technicians—actually work. A black-box model that offers recommendations without explanation is unlikely to be used, regardless of its statistical performance. Successful solutions augment domain expertise rather than attempt to replace it.
What It Takes To Make ML Work in the Field
Bridging these gaps requires deliberate changes in how ML research for oil and gas is framed and executed (Fig. 2).
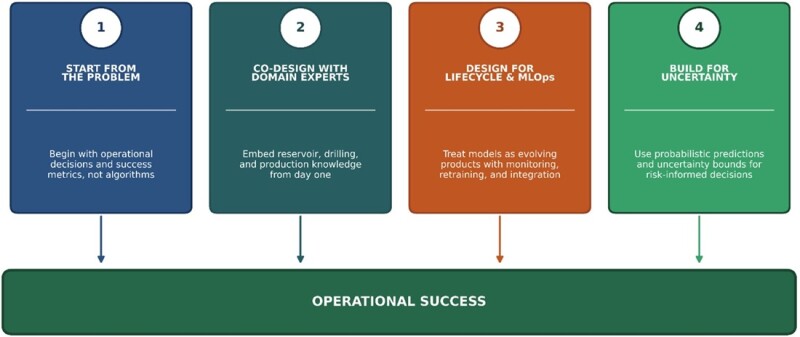
Start From the Problem. Research should begin with a clearly defined operational decision and success metric. Whether the objective is reducing nonproductive time, improving recovery efficiency, or minimizing downtime, model evaluation should reflect business value rather than accuracy alone. This requires researchers to invest enough time to understand operational constraints before selecting algorithmic approaches, ensuring that the problem formulation itself reflects industrial reality.
Co-Design With Domain Experts. Involve reservoir, drilling, and production engineers from problem scoping through validation. Their knowledge of rules of thumb, operational heuristics, and physical constraints should inform feature engineering, model architecture, and evaluation criteria. Research that incorporates domain expertise from the onset produces solutions that are better aligned with deployment realities. Researchers should treat domain experts as co-investigators, not just data providers or end users. This means researchers should document how domain knowledge shaped feature selection, data processing, and workflow integration. Transparent reporting links technical decisions to expert collaboration. This makes embedding domain expertise a recognized research contribution.
Design for Life Cycle and MLOps. Models should be treated as evolving products, not static artifacts. Research that explicitly considers deployment architecture, workflow monitoring, retraining triggers, and performance degradation offers a far clearer path to real-world impact. As the research firm Gartner predicted, 75% of enterprises are shifting from piloting to operationalizing ML in 2024 (Ammu 2025), but operationalization requires infrastructure that research must anticipate. Therefore, it is essential for researchers to meticulously outline data pipeline specifications, define integration procedures with operational systems, and offer an in-depth analysis of the model’s behavior under varying data distributions. Adhering to these practices enables robust implementation and adaptability in practical workflows, thereby enhancing the prospects for effective deployment and widespread adoption.
Build and Validate for Uncertainty. Subsurface systems are inherently uncertain, and ML research should reflect this. Probabilistic predictions, uncertainty bounds, and scenario-based validation are far more valuable to decision-makers than single-point estimates, particularly in high-risk operational environments. Probabilistic methods can provide substantially more accurate results than traditional approaches while also yielding confidence bounds that support risk-informed decisions (Andrais 2019). It is recommended that development teams explicitly characterize model behavior relative to operating envelopes and safety margins. They should also include validation studies that test how uncertainty estimates hold up on out-of-distribution data or during operational regime changes.
Lessons From Experience
To drive home the above points, we present an example of a project to predict reservoir porosity in real time, demonstrating the impact of domain expertise, putting operational reality in mind from the onset, and incorporating long-term operational efficiency in the design architecture.
The first consideration in achieving the real-time prediction is to ensure that only real-time data are used. Three such data sources were identified: drilling parameters, cuttings lithology volumes, and advanced mud gas (AMG) data. With the help of domain experts in the project team, we decided to focus, first, on the AMG data because it is the most objective and free from any human-induced uncertainty (Anifowose et al. 2025). Drilling data were noted to be sometimes subjective to the driller’s goal of completing the drilling process in a specific time. With this, the drilling parameters such as rate of penetration, rotational speed, and weight on bit, may not correctly align with the geological setting of the borehole (Srivastava et al. 2022). The cuttings lithology data were considered to be of low resolution because they are acquired at 10-ft intervals compared with the 1-ft intervals of the AMG data (Schlumberger 2015). Drilling parameters and cuttings lithology volumes were later integrated into the input features space after extensive quality check and normalization procedures to remove the effect of drilling anomalies and operational constraints as much as possible.
Domain experts in the team also suggested restricting the training data and prediction intervals to only the productive zones of the wellbore. This is because the physics governing the relationship between the mud gas data and porosity is applicable only in the productive zone. The use of advanced mud gas data was preferred over the basic mud gas data. The former covers more gas measurement ranges and, hence, would provide more relevant features than the latter. Finally, to ensure that the measured gas components are truly from the formation rather than the drilling fluid additives and to remove the background gas effect on the model training, a cutoff was applied on the total normalized gas (TNG) feature such that only the data points with the TNG greater than 100 ppm were used (Anifowose et al. 2022, 2023).
Overall, all these considerations and domain-expert contributions positively affected the success of the project, pilot, and eventual deployment into the production environment.
Conclusion
The gap between ML research and effective deployment in the oil and gas industry is not primarily a technical one. It is an alignment challenge between research questions and real decisions, between model design and operational constraints, and between innovation and the people expected to use it.
The tools and processes to achieve this already exist. What is needed now is a shift in mindset from proving what is possible to building what works.
References
Ammu, B. 2025. How To Detect and Overcome Model Drift in MLOps. Sigmoid, https://www.sigmoid.com/blogs/how-to-detect-and-overcome-model-drift-in-mlops (accessed (27 March 2026).
Andrais R. 2019. Probabilistic Oil and Gas Production Forecasting Using Machine Learning. Master’s thesis. Massachusetts Institute of Technology, Cambridge, Massachusetts (September 2021).
Anifowose, F., Mezghani, M., Badawood, S., and Javed, I. 2022. A First Attempt To Predict Reservoir Porosity From Advanced Mud Gas Data. International Petroleum Technology Conference, Riyadh, Saudi Arabia. IPTC-22061-EA. https://doi.org/10.2523/IPTC-22061-EA.
Anifowose, F., Mezghani, M., Badawood, S., and Javed, I. 2023. From Well to Field: Reservoir Rock Porosity Prediction From Advanced Mud Gas Data Using Machine Learning Methodology. Middle East Oil, Gas, and Geosciences Show, Manama, Bahrain. SPE-213339-MS. https://doi.org/10.2118/213339-MS.
Anifowose, F., Badawood, S., and Mezghani, M. 2025. AiLAB: An In-house Developed Codeless Platform for Machine Learning Modeling. Proc., Fifth EAGE Digitalization Conference and Exhibition, Edinburgh, Scotland, 24–26 March, https://doi.org/10.3997/2214-4609.202539090.
Bhadauria, S. 2025. Maximizing the Impact of AI in the Oil and Gas Sector. EY, 6 January 2025, https://www.ey.com/en_us/insights/oil-gas/maximizing-the-impact-of-ai-in-the-oil-and-gas-sector (accessed 27 March 2026).
Póvoas, A., et al. 2025. Artificial Intelligence in the Oil and Gas industry: Applications, Challenges, and Future Directions. Applied Sciences, 15 (14), 7918. https://doi.org/10.3390/app15147918.
Schlumberger 2015. The Defining Series: Mud Logging. Ed.: Varhaug, M., Oilfield Review, 2015.
Srivastava, S., Shah, R.N., Teodoriu, C., and Sharma, A. 2022. Impact of Data Quality on Supervised Machine Learning: Case Study on Drilling Vibrations, J. Pet. Sci. Eng. 219: Article 111058. https://doi.org/10.1016/j.petrol.2022.111058.
Zaman, S. 2025. Major MLOps Challenges and How To Solve Them. Folio3, 30 September 2025, https://cloud.folio3.com/blog/mlops-challenges (accessed 27 March 2026).
Disclaimer: The views expressed in this article are those of the author and in no way represent those of his affiliates.
