

Over the course of an offshore project’s operation, flow-related issues are likely to manifest. The levels of difficulty and consequence may vary, but for a variety of reasons their underlying cause is not immediately obvious. In such circumstances, an investigation of fluid flow behavior based on an understanding of the first principles of flow assurance is necessary, an expert said.
In a presentation held by the SPE Flow Assurance Technical Section, Trevor Hill spoke about the principles and practices that arose from lessons learned in BP’s flow assurance operations. Hill is a senior flow assurance advisor at BP.
Hill described three principles that should guide any analysis of a flow assurance incident. First, the laws of physics always apply: In many cases, the key to determining the cause of a problem is recognizing which law of physics is most applicable to the circumstances. Second, common sense about flow assurance usually provides the key to understanding: Flow assurance experts should have a basic idea of what happens in a flowing system.
The third principle is that, despite one’s knowledge of flow assurance and general physics, unusual events beyond a person’s understanding can still occur within a system. Hill said a consultant should be prepared for anything.
“Sometimes we just have to acknowledge that something strange has happened. We’ve understood the physics, we’ve understood the data, but we still can’t understand the issue until we’ve taken into account some other phenomenon,” he said.
When tackling a flow assurance incident on-site, Hill said consultants should first gather the opinions of the operations team members, since they have a day-to-day understanding of what should happen under normal circumstances and better familiarity with the available data. He said the key to talking with operators is to avoid a confrontational or accusatory tone of discussion, so as to gain their trust and create an environment where frank discussion can take place more freely.
“It’s not about confrontation or finding out who’s done something wrong,” Hill said. It’s about this being our issue together, and we want to help find it. You have to keep an environment where you can go back—here’s initially what was said, but now we’ve got a list of follow-up questions—and we need to keep that communication open.”
After getting the operator’s view, the consultant must develop his or her own understanding of the system in question. This involves learning the topography of the field; the schematic layout of the facilities, pipelines, flowlines, and risers; and the sources of flow, pressure, and temperature. Hill said a best-case scenario is for an operator to have an as-built transient model of the system available for analysis. From there, the consultant should obtain all process data and logs for the incident, check them against the process data for normal conditions, and develop a timeline.
Hill said a formal timeline of the incident is crucial because it can help consultants and operators better understand what exactly transpired.
“In the heat of the moment, with people thinking back to what they think happened, things can actually get out of order and, as that timeline gets written out, actually things may not connect properly,” Hill said.
Developing a theory for the cause of an incident requires rigorous testing and constant revision of the theory. Hill said it is important to be careful in this step of the evaluation; consultants should ascertain the operator’s confidence in the instrumentation on-site and check for abnormalities in the ambient conditions around a field.
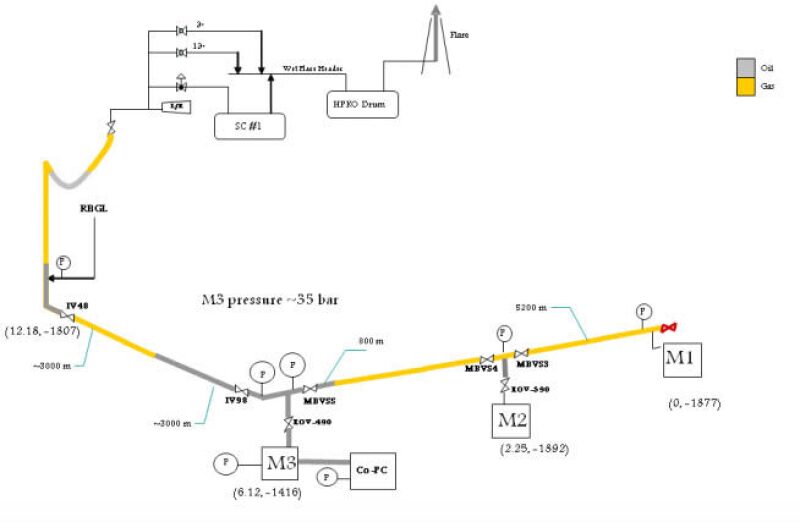
He discussed several examples of flow assurance incidents that BP encountered in its operations. One such incident involved the buildup of hydrates in a deepwater flowline, represented in Fig. 1 as a bold yellow line running from a set of manifolds (M1, M2, M3), during a system restart. During the restart, the riser-based pressure gauge showed a value significantly higher than normal—160 bar, 20 bar higher than the normal restart pressure.
The extra pressure suggested a hydrate buildup in the flowline, but because the field was an early life field with no water cut, Hill said that hypothesis was difficult to accept initially.
“That’s when we get into the laws of physics,” he said. “You can’t form hydrates without water, so there’s an operational response to the awareness of hydrates as an issue, but we couldn’t come and say fundamentally we don’t think it could be that. So what really did happen in this case?”
When the system was shut down, the differential pressure across the riser started at approximately 7 bar, and the differential pressure across the flowline was approximately 4 bar. As the liquids settled out, the temperature in the flowline dropped, causing the gas to contract and suck some of the liquid that was in the riser back into the flowline. This caused a drop in the riser differential pressure to approximately 4.5 bar.
After a day-and-a-half, the differential pressures across the riser and the flowline unexpectedly started to rise again. This was due to a small, but noticeable, seawater ingress upstream of the riser top valve. Fluid had entered the system, gotten into the flowline, and filled it, leading to the increased backpressure.
Hill said the incident was an example of how a tiny malfunction could cause a major problem.
“We had a higher differential pressure than we’d ever seen on this one little component that was one failure out of a multitude of components,” he said.
This webinar is available at https://webevents.spe.org/products/operational-flow-assurance.