

Building a useful machine learning (ML) product involves creating a multitude of engineering components, only a small portion of which involve ML code. A lot of the effort involved in building a production ML system goes into things such as building data pipelines, configuring cloud resources, and managing a serving infrastructure.
Traditionally, research in ML has largely focused on creating better and better models, pushing the state-of-the-art in fields such as language modeling and image processing. Less of a focus has been directed toward best practices around designing and implementing production ML applications at a systems level. Despite getting less attention, the systems-level design and engineering challenges in ML are still very important—creating something useful requires more than building good models, it requires building good systems.
ML in the Real World
In 2015, a team at Google created the following graphic:
It shows the amount of code in real-world ML systems dedicated to modeling (little black box) compared to the code required for the supporting infrastructure and plumbing of an ML application. This graphic isn’t all that surprising. For most projects, the majority of headaches involved in building a production system don’t come from the classic ML problems such as over- or underfitting but from building enough structure in the system to allow the model to work as it’s intended.
Production ML Systems
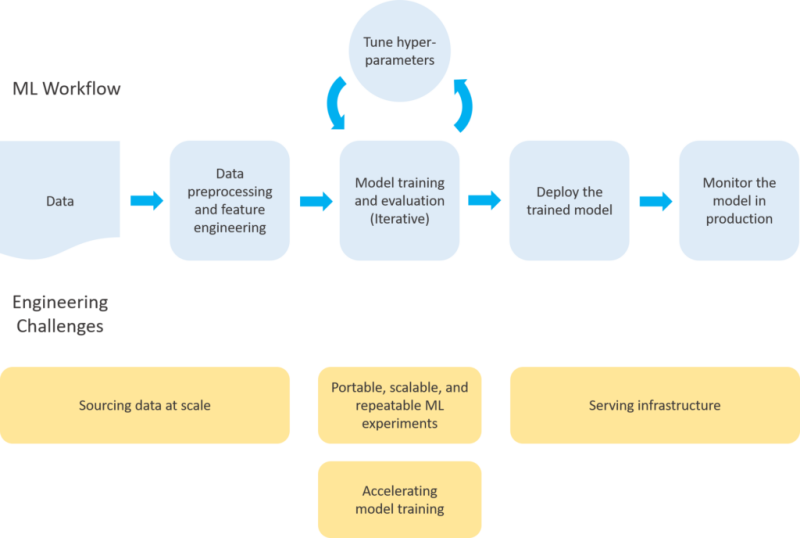
Building a production ML system comes down to building a work flow—a series of steps from data ingestion to model serving, where each step works in tandem and is robust enough to function in a production environment.
The work flow starts from some data source and includes all of the steps necessary to create a model endpoint—preprocessing the input data, feature engineering, training and evaluating a model, pushing the model to a serving environment, and continuously monitoring the model endpoint in production.
The feature engineering > training > tuning part of this work flow is generally considered the ‘art’ of machine learning. For most problems, the number of possible ways to engineer features, construct a model architecture, and tune hyperparameter values is so vast that data scientists/ML engineers rely on some mixture of intuition and experimentation. The modeling process is also the fun part of machine learning.
Modeling vs. Engineering
This modeling process is largely unique across different use cases and problem domains. If you’re training a model to recommend content on Netflix, the modeling process will be very different than if you’re building a chatbot for customer service. Not only will the format of the underlying data be different (sparse matrix vs. text) but also the preprocessing, model building, and tuning steps will be very different. But, while the modeling process is largely unique across use cases and problem domains, the engineering challenges are largely identical.
No matter what type of model you’re putting into production, the engineering challenges of building a production work flow around that model will be largely the same.
The homogeneity of these engineering challenges across ML domains is a big opportunity. In the future (and for the most part today) these engineering challenges will be largely automated. The process of turning a model created in a Jupyter notebook into a production ML system will continue to get much easier. Purpose-built infrastructure won’t have to be created to address each of these challenges, rather the open-source frameworks and cloud services that data scientists/ML engineers already use will automate these solutions under the hood.