

Introduction
In recent years, detection and alerting systems have been applied to numerous drilling failures, including stuck pipe, fluid influx/loss, and drilling dysfunctions. But the detection of drillstring washout and mud pump failure has been left primarily to traditional methods that rely solely on standpipe pressure and pump rates or on measurement-while-drilling (MWD) sensor data.
Drillers commonly use a simple hydraulic coefficient relating standpipe pressure to pump rate to detect drillstring washouts. MWD pressure and mud motor data may improve detection but this approach remains problematic owing to poor-quality sensor data and various factors that affect flow and pressure data. As a result, drillers often do not recognize a crack in the drillstring before it grows into a washout that may cost operators hundreds of thousands of dollars in lost time, equipment replacement, and fishing operations.
Drillers also rely on standpipe pressure changes to detect mud pump failures and degradation from damaged pump parts. High-frequency pump pressure data may enhance pump wear detection and accelerometer data may be used to infer valve leaks, but these solutions are impractical in most field applications.
To address these shortcomings, a methodology has been introduced using basic rig sensors and contextual information to detect various drilling failure modes. It has applied that same approach to early washout and pump failures detection and alerting.
Methodology
The detection and alerting system uses a Bayesian network, which aggregates key sensor inputs and contextual data and predictions from hydraulic modeling. Cumulatively they are the inputs to a probabilistic belief system. The probabilistic model outputs belief values of between 0 and 1 that are indicative of specific drilling, equipment, and sensor failures.
Just as the human brain uses experience to generate beliefs upon which to act and react to the world around it intelligently, the probabilistic model uses past and present trends and artificial intelligence (AI) to generate beliefs about drilling dysfunctions and equipment failures. The model also assesses these trends to increase its accuracy through self-learning and self-calibration that enables it to adjust for poor sensor data, drilling conditions, and model uncertainties. As a consequence, when the value of a belief rises to a specified level and the system triggers an alert, the driller can act upon it with increased certainty that it is not a false alarm.
Bayesian networks consist of discrete, or continuous-valued, nodes. Nodes are connected via conditional probability tables (CPTs) and linked by arrows generally representing the direction of causation. Each CPT is assigned a specific weight based on its relative impact on specific outcomes.
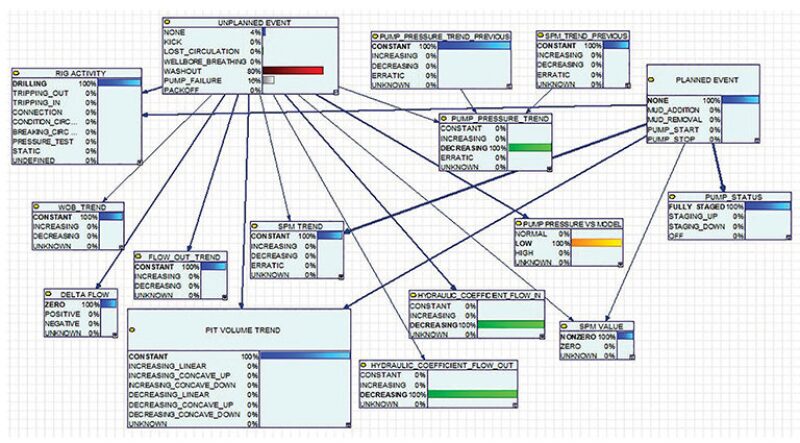
A Bayesian Network in which the key node is “Unplanned Event” includes several event types and their associated probabilities, or beliefs. This network arrangement can be used to detect a broad variety of incidents related to well control and hydraulics, such as washouts, pump failures, kicks, lost circulation, wellbore breathing, packoff and others to which a probability value is assigned.
The network also includes a “Planned Events” node to account for such events as pump start-stop routines or mud volume changes. This node eliminates false alarms that may be raised, for example, during and immediately following pump startup when standpipe pressure and flow rate data might be otherwise misinterpreted by the network as a washout.
The other nodes are made up of processed real-time inputs, such as current and previous pump pressure and strokes per minute, over a 2-minute window. Statistics and curve-fitting techniques are used to determine if a trend is constant, increasing, decreasing, or erratic. The self-calibrating network aggregates trends in the data and infers the individual beliefs for events such as washouts and pump failures. These beliefs are processed into an alerting and reporting module that is delivered as part of a driller-friendly real-time data aggregation system.
To detect and initiate alarms of impending washouts and pump failures, the developers focused on time signatures of real-time and modeled pump pressure in relation to flow rate trends. Together these parameters describe the status of the equipment, which is then assessed through real-time alerts.
Fig. 1 illustrates the Bayesian Network predictions for a hypothetical washout scenario during which all relevant signatures are satisfied. Because it is the maximum attainable value for this network configuration and CPT, the washout probability only rises to 80%. If only partial signatures are observed, the washout probability is reduced further. A similar calculation can be performed for mud pump failure with a maximum probability of 93%. The thicker arrows in the figure indicate features having significant influence on the event process.
Learning of Bayesian Network CPTs
After defining the Bayesian Network, the system learns CPTs associated with one or more variables and the CPT parent nodes by using a training data set of labeled events and the corresponding detection features. Missing fields in the training data can be completed using an optimization algorithm.
A data set for learning the CPT associated with washout detection can be provided to the learning engine as soon as the events can be labeled by a human or by third-party detection software. CPTs can be fixed during the learning process to maintain previously learned parameters. The learning process may be stopped after a number of samples are collected and be restarted when drilling conditions or measurements have substantially changed.
After the CPTs have been learned from the labeled training data set and applied to the Bayesian Network illustrated in Fig. 1, the washout detection probability is raised from 80 to 100%. In addition, the influence, as indicated by the arrow thickness, of some nodes will increase.
Alerting Procedure
The system alerts operators to potential washouts and pump failures in two phases. It first automatically tracks a moving average of the summed washout and pump failure beliefs. If these beliefs cross a certain threshold, the system alerts the drilling engineer through a report containing the event beliefs as well as pressure and flow trends. In the second phase, the engineer analyzes the trends to determine the likelihood that a washout or pump failure is occurring.
Because washout and pump failure modes share most of the same signature points, the first phase establishes that either a washout or a pump failure is happening or about to happen. By tracking washout and pump failure beliefs as one, rather than attempting to identify each belief individually, the number of false alarms is essentially halved. The second phase serves to identify precisely which type of failure is representative of the automatically generated alarm.
Case Studies
The belief-based automated alerting system (Fig. 2) deployed on a rig for an operator in North America generated three alerts 6 hours prior to the rig crew tripping out to address a washout. The crew was thus alerted to the washout before it became enlarged and caused significant problems, such as a twistoff. Catastrophic failure aside, early event detection by the automated system allowed the crew to proactively address the problem and return to normal operations quickly, which significantly reduced nonproductive time.
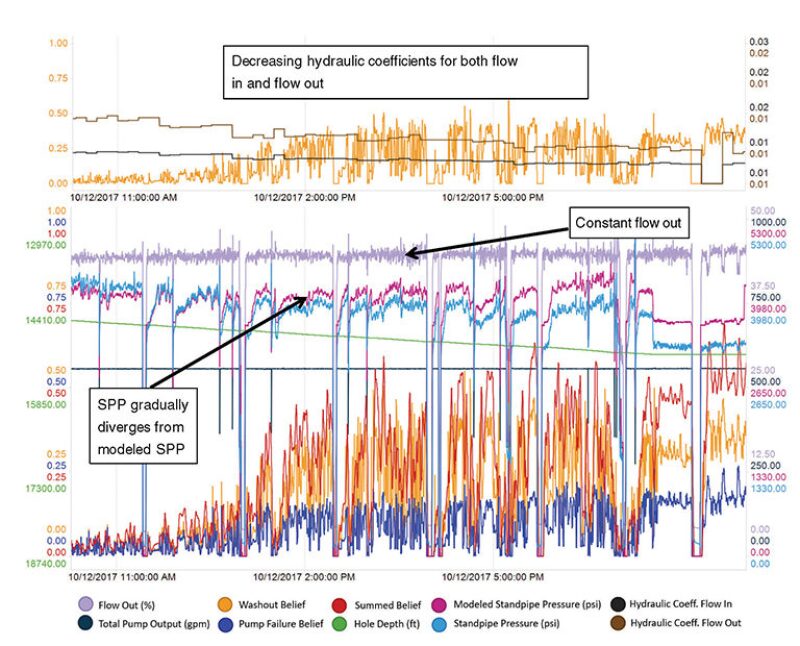
On another well, the system was able to distinguish between a washout and a pump failure. The prime indicator that an event was underway was a sudden and unexpected drop in standpipe pressure. At the same time, the flow-out rate changed only subtly and shifts from the flow-out trend were constant and did not decrease until long after the decrease in standpipe pressure occurred.
After correcting the washout, the crew drilled ahead amid clear indications that the flow-out measurement was decreasing compared with the flow-in rate based on pump strokes per minute. In addition, the hydraulic coefficient flow out remained constant, while it decreased for flow in. These data increased the pump failure belief, which led the crew to perform needed maintenance on the swivel and the rig’s three mud pumps.
Conclusions
Case studies indicate that through continuous model improvements and validation, operators are able to detect the warning signs of washout and pump failure hours before the problem can be detected at the rigsite. In addition, these case histories demonstrate the significant value added through early detection of mechanical failures by significantly reducing nonproductive time caused by pump downtime, tripping, and fishing.
This article contains highlights of paper SPE 189700, “Self-Learning Probabilistic Detection and Alerting of Drillstring Washout and Pump Failure Incidents During Drilling Operations,” by A. Ambrus, formerly with Intellicess; P. Ashok, D. Ramos, A. Chintapalli, Intellicess; A. Susich, T. Thetford, B. Nelson, M. Shahri, J. McNab, and M. Behounek, Apache Corp., presented at the 2018 IADC/SPE Drilling Conference and Exhibition, Fort Worth, Texas, 6–8 March.