

Traditional statistics has been around for more than a century. Actually, the term was coined in Germany in 1749. If its connection with probability theory (randomness) is taken into account, then its history may even go as far back as the 16th century. Nevertheless, the point is that, unlike artificial intelligence (AI) and machine learning (ML), traditional statistics is not a new technology.
In order to develop a better understanding of the fundamental differences between these two technologies, one should start with the seminal paper written by Leo Breiman, a well-known professor of statistics from University of Berkeley (Statistical Modeling: The Two Cultures). Written by a highly respected statistician, this important archival paper can serve as great start in realizing the differences between traditional statistics and AI and ML. After reading that paper, in order to develop a more detailed understanding of the differences between these topics, one must then read the book written by Nisbet, Elder, and Miner (Handbook of Statistical Analysis & Data Mining Applications). This book explains the different philosophies that form the foundations of these technologies.
One may wonder why I am writing about the differences between AI and ML and traditional statistics. The reason has to do with the fact that there are some individuals and some startup companies in the oil and gas industry that refer to linear regression as machine learning and believe these two technologies are the same. In a previous essay, I mentioned that “when some people refer to linear regression as machine learning, it tells you volumes about their understanding of these technologies.” When they refer to “data analytics,” they mostly refer to linear or nonlinear regression or multivariate regression and try to treat them as a new technology. Often, people who either intentionally or unintentionally make such mistakes also try to refer to these traditional and old technologies as something that is new in our industry.
This clarifies one of the reasons behind the superficial understandings of AI and ML that currently has overwhelmed many operating companies in the oil and gas industry (specifically those operating in shale plays). The problem is that, when vendors, service companies, startups, or even employees in the operating companies that call themselves “data scientist” fail to achieve the results that they promise, they either blame the AI and ML or try to reuse and combine traditional mathematical formulations of their understanding of the physics with data and call them hybrid models. The key is that combining traditional mathematically formulated physics-based approaches with data-driven analytics completely overrules the main reasons behind using AI and ML to solve complex physics-based problems. Unfortunately, a large number of engineers seem to fail to realize this fact. The objective here is to note that those who fail to deliver the promised results blame AI and ML and then add the term “physics” to “data” and “AI.” I consider such phrases indicative of a lack of expertise in data-driven modeling technologies.
What they seem to forget is that the use of traditional statistical approaches in the oil and gas industry goes back to the early 1960s. Arp’s decline curve analysis (DCA) is a good example of statistical regression. Capacitance/resistance modeling (CRM) is another example of using traditional statistical analysis to analyze production data. Initial use of geostatistics in the mining industry that later was incorporated in numerical reservoir (geological) modeling goes back to the early 1950s. Therefore, as far as the application of the traditional statistics in the oil and gas industry is concerned, nothing is new about this technology. I hope no one misinterpret this as a criticism of DCA, CRM, or numerical reservoir (geological) simulation. I have immense amount of respect for these technologies and their historical contribution to our industry. The objective is to identify the facts regarding the category of science to which each technology belongs. Mistakes made in doing so usually result in many misunderstandings that are associated with the qualities; capabilities; and, at the same time, limitations and shortcomings of each specific technology or scientific category.
The fact that traditional statistics-based technologies use data to accomplish their objectives does not mean that they are capable of doing the same things that are done by AI and ML. The first applications of AI- and ML-related technologies in the upstream oil and gas industry took place in the early 1990s. The early 2000s saw, for the first time, AI and ML algorithms applied to reservoir engineering and reservoir modeling. Unlike the statistics-based technologies of DCA and, to a certain extent, CRM, the approach of AI and ML to reservoir modeling is not limited to production data or, in some cases, injection data. Because reservoir-modeling technology that is based on AI and ML tries to model the physics of fluid flow in the porous media, it incorporates every piece of field measurements (in multiple scales) that is available from the mature fields. Statistical-related approaches start with identifying a particular approach to fulfill a given objective. Then they go to the mature field and select the data that they require and then accomplish their objectives. AI and ML does it in a different fashion. Because the objective is reservoir simulation and modeling, the AI and ML approach uses any and all the measured data from a mature field and use them all to build a reservoir simulation model by modeling the fluid flow in porous media.
Data-driven reservoir modeling that uses AI and ML incorporates field measurements in multiple categories and multiple scales. Examples of parameters used in data-driven reservoir modeling are well-placement and -trajectory data, seismic data, well logs, core analyses including special core analysis, pressure/volume/temperature data, details of completion, workover, stimulation including hydraulic fracturing, artificial lift, operational constraints, and detailed production and injection data. These parameters are collected and used from every well in the field, regardless of whether they are producing or have been abandoned. This technology develops a coupled reservoir/wellbore model. Data-driven reservoir modeling simultaneously history matches oil, gas, and water production as well as reservoir pressure and water saturation using only operational constraints such as choke setting or the wellhead (not the bottomhole) pressure as the only required input to the model (Data Driven Reservor Modeling).
Traditional statistics has an Aristotelian approach to problem solving and a deductive approach to the truth, while the philosophy behind AI and ML is Platonic and includes an inductive approach to the truth. While traditional statistics tests hypotheses through parametric models and compares them to the standard metrics of the models, AI and ML builds models using the data instead of starting with a model and testing the data to see if it fits the predetermined models. AI is defined as mimicking nature, life, and the human brain to solve complex and dynamic problems. Neural networks mimic neurons in the human brain, fuzzy set theory mimics human logic and reasoning, and genetic algorithm mimics Darwinian evolution theory. ML is defined as a set of open computer algorithms to learn from data instead of explicitly programming the computer and telling it exactly what to do (as we do in numerical reservoir simulation). The human brain does not use Aristotelian tow-valued logic (e.g., yes/no, black/white, true/false, 0/1) in order to solve problems and make decisions. Probability theory addresses uncertainties that are associated with randomness not uncertainties associated with lack of information.
Statistical approach starts with a series of predetermined equations (set of hypotheses) such as single or multivariable linear regression or nonlinear regression that is well defined (e.g., logarithmic, exponential, quadratic). Then, it tries to find the most appropriate predetermined equation that would fit the collected data. While the traditional statistical approach tries to find correlations between the involved variables, it does not address or takes into account, or even try to identify, causations from the data. Everyone knows that correlation does not necessarily addresses causation. Figs. 1 and 2 are good examples of such an issue.
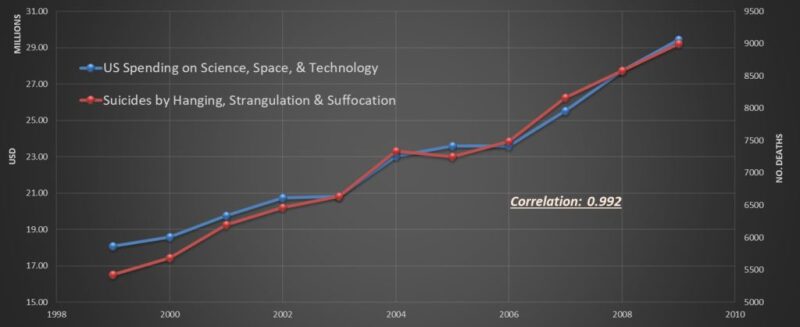
of US spending on science, space, and technology
with the number of suicides by hanging, strangulation,
and suffocation clearly does not imply causation.
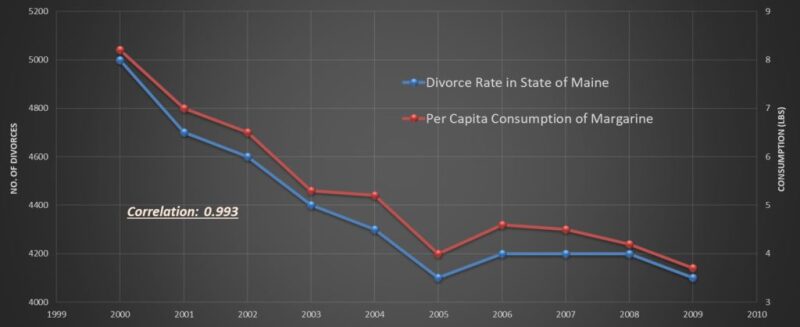
between the divorce rate in state of Maine
and the per capita consumption of margarine.
AI and ML do not start with any predetermined models or equations. They does not start with any assumptions regarding the type of behavior that variables may have in order to correlate them to the target output. The characteristics of AI and ML is to discover patterns from the existing data. The strength of the open AI and ML algorithms has to do with their amazing capabilities to discover highly complex patterns within the large amounts of variables. The final outcome of the models that are developed by AI and ML algorithms usually cannot be summarized by one or by a few equations. That is why many engineers like to use the term “black box.” Apparently, traditional engineers cannot make sense of models unless they include one or more well-defined mathematical equations that they have grown up with since they started college. Most probably, that is the reason behind calling the AI and ML related models black box models. What the traditional engineers who do not respect new technologies seem not to realize is that, from a mathematical point of view, the models that are developed using AI and ML include a series of matrices that generate the models’ outcomes. Therefore, nothing is opaque (black) about these models (boxes). The fact is that, when you ask a question from an AI-based model (as long as it has been developed correctly), it can respond in a very solid manner.
Fig. 3 summarizes one of the major differences between traditional statistical approach to problem solving with the approach that is used by AI and ML. When data is used in the context of traditional statistical approaches, a series of predetermined equations are used in order to find out how to fit the data. In other words, the form and shape of the equation that will be fitting the data set and sometimes even the form of the data distributions are all predetermined. In such cases, if the actual data is too complex to fit any predetermined equations or distributions, then either the approach to solving the problem comes to a standstill or large number of assumptions, simplifications, and biases are incorporated into the data (or the problem) in order to come to some sort of a solution.
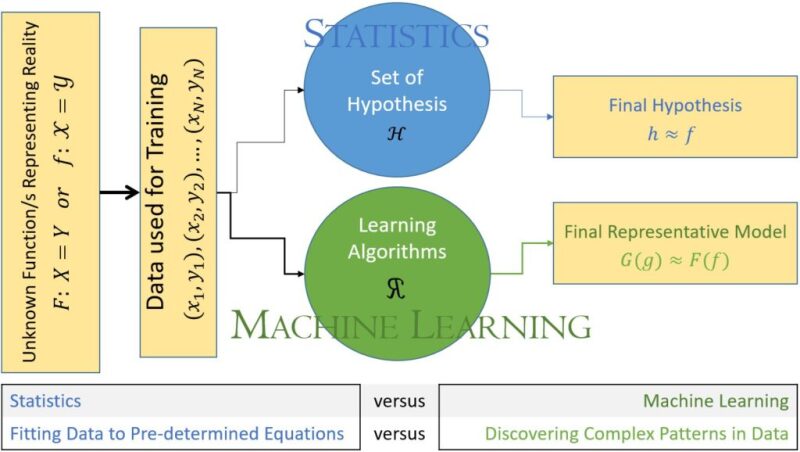
Inspired by a lecture given by Yaser Said Abu-Mostafa,
a professor of electrical engineering and computer science
at the California Institute of Technology.
Fig. 4 shows a summary of some of the algorithms that are used in the traditional statistical approaches vs. some of the algorithms that are used in AI and ML. Having a solid knowledge of statistics is a requirement for being an expert practitioner of AI and ML. However, it is important not to confuse these two technologies with one another. When it comes to “modeling the physics” of the engineering-related problems from data using AI and ML, no predetermined set of equations are used to fit the data. The main reason for this separation is the avoidance of biases, preconceived notions, gross assumptions, and problem simplifications when AI and ML is used to model and find solutions for the physics of the engineering related problems.
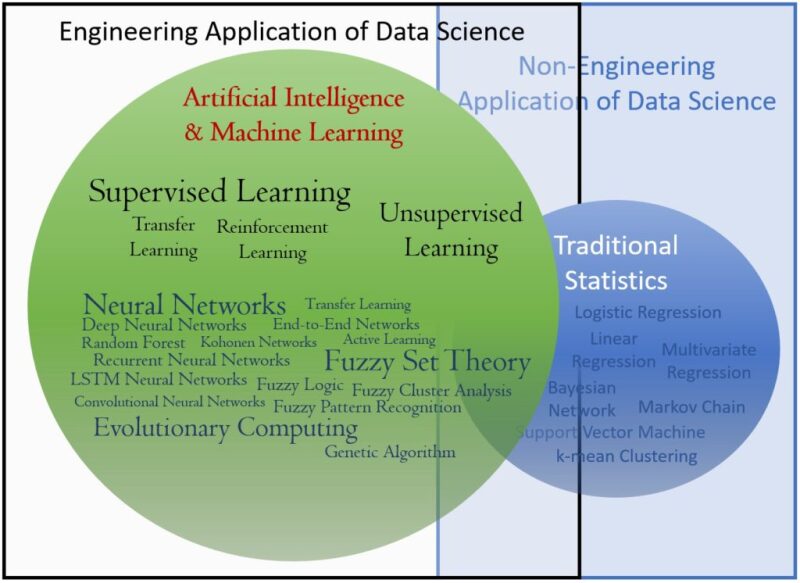
by traditional statistics vs. AI and ML.
Using AI and ML for modeling is all about the data. Data that, in our industry in most cases, are field measurements must guide the solutions that are reached, not today’s understanding of the physics that is modeled using mathematical equations. The fact is that field measurements represent the physics of the problem that is being modeled; therefore, by using the data that represents the physics, this approach becomes a physics-based problem solving. Data (field measurements) represent the physics that is being modeled.

Mohaghegh has authored three books (Shale Analytics, Data Driven Reservoir Modeling, and Application of Data-Driven Analytics for the Geological Storage of CO2) and more than 170 technical papers and has carried out more than 60 projects for independents, national oil companies, and international oil companies. He is an SPE Distinguished Lecturer (2007–08) and has been featured four times as the Distinguished Author in SPE’s Journal of Petroleum Technology (2000–04). Mohaghegh is the founder of Petroleum Data-Driven Analytics, SPE’s Technical Section dedicated to artificial intelligence and machine learning. He has been honored by the US Secretary of Energy for his AI-related technical contribution in the aftermath of the Deepwater Horizon accident in the Gulf of Mexico and was a member of US Secretary of Energy’s Technical Advisory Committee on Unconventional Resources in two administrations (2008–14). Mohaghegh represented the United States in the International Standard Organization in Carbon Capture and Storage (2014–16).
