

In the oil and natural gas industry, the continuous operation of offshore rotating equipment is essential for maintaining production efficiency and minimizing expenses. Traditional maintenance approaches, such as reactive and time-based methods, are often insufficient to address the challenges of offshore environments. These approaches typically rely on fixed schedules or respond to breakdowns after they occur, leading to increased downtime and higher maintenance costs.
Predictive maintenance, enhanced by artificial intelligence (AI) and machine learning (ML), is a potential shift toward proactive maintenance strategies. By using real-time and historical data, coupled with ML algorithms, predictive maintenance systems can predict equipment failures before they occur, allowing for better maintenance schedules. This approach not only improves equipment reliability and maximizes uptime but also reduces operational disruptions.
This paper outlines a project by Murphy involving the implementation of an AI/ML-based predictive maintenance method across its deepwater platforms in the Gulf of Mexico. The project focused on production-critical rotating equipment, including turbines, compressors, and pumps. By integrating data from multiple sources and deploying predictive models, the project aimed to improve operational reliability and provide valuable insights to the maintenance teams. The project explored both the transformative potential of predictive maintenance in offshore environments and the many challenges that come along with it.
Methodology
Murphy embarked on a transformative journey by partnering with a service provider to implement AI/ML-based predictive analytics on its rotating equipment. The scope of the project was to explore and experiment with AI/ML-based predictive maintenance to maximize equipment uptime and to get early breakdown warnings on production-critical equipment. The AI/ML-based predictive maintenance solution was deployed for 24 months on two deepwater platforms in the Gulf of Mexico, and select production critical rotating equipment was monitored: turbines, natural-gas compressors, pumps, and glycol system.
This project was executed in several planned stages, each contributing to the overarching goal of enhancing operational reliability and efficiency.
In the typical data flow described in Fig. 1, the process begins with the sensor capturing process data. This data is initially stored in an offshore historian, which acts as the first repository. The offshore historian plays a vital role in ensuring that the data is securely held for a short duration and readily accessible for initial analysis or immediate operational needs.

Following this, the data is systematically transferred to an onshore historian. This transfer is a critical step, allowing for comprehensive review and long-term storage of the data. The onshore historian provides personnel with the capability to analyze and review the data whenever required, facilitating informed decision-making and operational efficiency.
Before the implementation of the predictive maintenance project, as illustrated in Fig. 2, the data flowed from the sensor to the historian at Murphy involved several steps. Initially, the sensor captured the process data, which was then transmitted directly to the offshore historian. This historian served as a primary repository, storing the extensive data generated by the sensors.
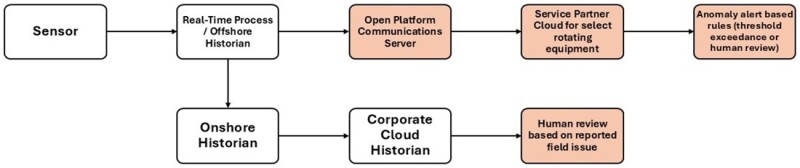
Data from export natural-gas compressors and main power-generation turbines was transferred via an Open Platform Communications (OPC) server, an intermediary, to the equipment service partner’s cloud. The service partner reviewed the data and set up alerts based on predefined thresholds. If a threshold is exceeded, the service partner manually reviews the data and notifies the company if any maintenance actions are required.
For the remaining rotating equipment, data was transferred from the offshore historian to the onshore historian, where it was reviewed by personnel as needed.
Initially, instrument data from the sensors was transferred to the service partner’s cloud environment. For the main power-generation turbines and export natural-gas compressors, data was manually scraped from the service partner’s web interface. To streamline this process, a dedicated data pipeline was established to periodically transfer the scraped data to the service partner’s cloud. This setup facilitated the application of advanced predictive analytics algorithms to the rotating equipment data, laying the groundwork for predictive maintenance and early anomaly detection.
To develop robust predictive models, the time-series data from sensors was enhanced with event-based data, including equipment history from the Computerized Maintenance Management System (CMMS) and daily progress reports. Initially, the CMMS data transfer was performed manually using spreadsheets. Recognizing the necessity for a more efficient process, a Representational State Transfer Application Programming Interface (REST API) was subsequently established to automate the transfer of CMMS data to the service partner’s cloud.
This automation facilitated the continuous and seamless incorporation of maintenance records and operational data into the predictive models. Moreover, during this stage, the manual data scraping from the cloud was eliminated by directly transferring the relevant data to the onshore historian via an OPC server.
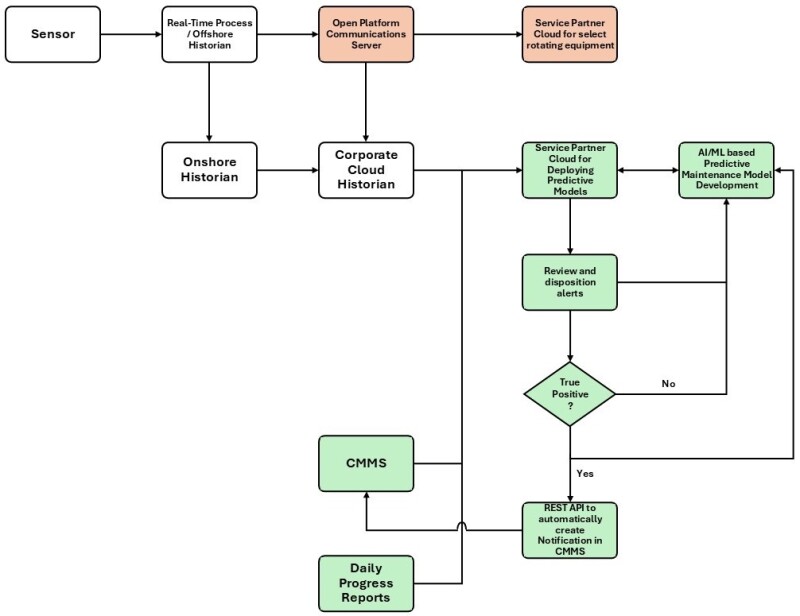
After the models were developed and deployed in the cloud, they began generating anomaly alerts. These alerts required review to classify them as true or false positives. The classification results were then fed back to the model development team to retrain the models continually. True positives were used to manually create maintenance notifications in the CMMS, ensuring timely maintenance execution.
As predictive models began generating actionable insights, notifications were initially created manually in the CMMS. To enhance efficiency, another REST API was developed during this stage to create notifications in the CMMS for true positives, ensuring timely maintenance execution. This seamless integration ensured that Murphy’s offshore maintenance teams received alerts for potential issues, enabling proactive interventions and minimizing downtime. Fig. 3 shows the final workflow that enabled automated notifications to the CMMS.
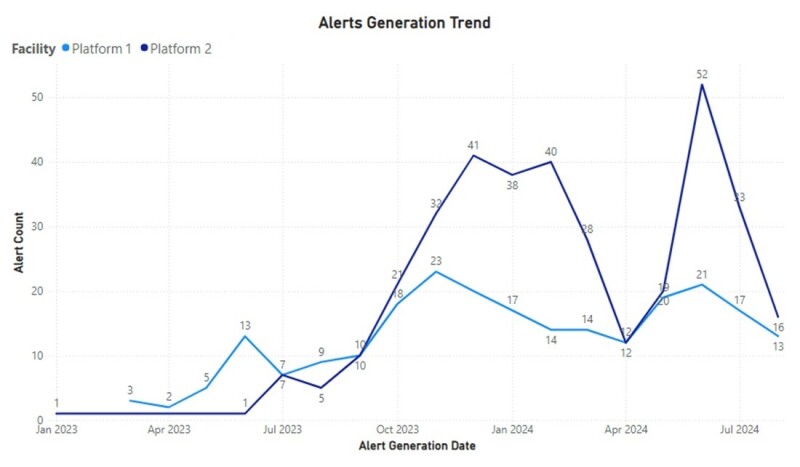
Observations A total of 46 predictive models were deployed in the cloud for the various types of rotating equipment, and each platform had a unique set of models. Alerts generated by each model were recorded and dispositioned. Fig. 4 shows the alert generation trend for both platforms. Models for Platform 2 started generating alerts in January 2023, while models for Platform 1 started generating alerts in March 2023 because these models were deployed later. Cumulatively, while more alerts were generated by the models deployed on Platform 2, that was not a reflection of actual uptime or safety performance of the two platforms.
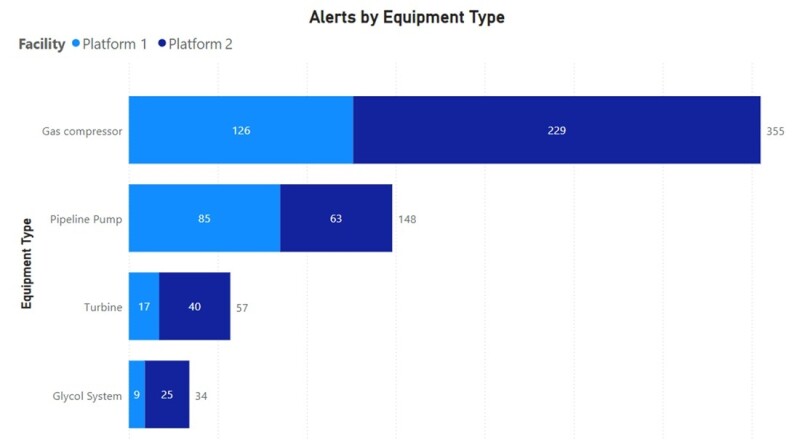
Fig. 5 shows alert count by each equipment type.
The alerts were reviewed and categorized by a cross-functional review team, which included members from the AI/ML software service partner and Murphy’s facility and process engineering, reliability engineering, maintenance, and operations teams. If necessary, additional support was sought from the equipment service partner during the review process.
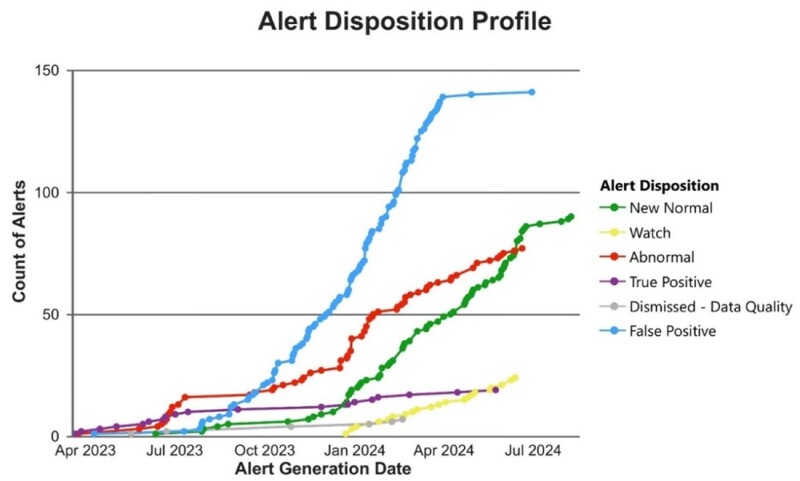
It is important to note that the incidence of false positives increased as more models were deployed. Following the disposition of these alerts and subsequent model retraining, however, the rate of false positive alerts significantly decreased. Fig. 6 illustrates the trend in alert disposition.
Discussion
Project Planning and Management. Understanding of Project Prerequisites. A pilot project was first implemented where a data set with a known failure was meant to be evaluated through the AI/ML-based predictive maintenance process from various companies. The evaluations received from the service partners showed that their models were able to identify the failure in advance, each at varying lead times (between 100 and 121 days in advance). In addition, each predictive maintenance process required varying levels of input from Murphy to correctly set up the model to interpret the data set. This method provided the team with high expectations that it could be executed with not much additional effort besides data connectivity, but there was a lot more to be understood before being ready for a full-scale predictive maintenance project.
One of the significant challenges encountered during the project was the initial lack of understanding of the project prerequisites. This led to several startup challenges, including delays and misalignments in the project’s early stages. It is crucial for future projects to ensure a comprehensive assessment and understanding of all prerequisites before the project commencement. This step includes detailed planning sessions, stakeholder meetings, and feasibility studies to identify potential roadblocks and address them proactively.
Additionally, a clear business case for using an AI/ML-based predictive maintenance process should have been identified, outlining specific objectives and expected outcomes. Understanding the resources, skills, and technologies required to execute such projects is essential to ensure successful implementation and integration. By establishing these foundational elements, projects can be better structured, reducing the likelihood of unforeseen issues and enhancing the overall effectiveness of the solution.
Data Prerequisites: Completeness and Quality. One of the pivotal aspects that influenced the project’s timeline and effectiveness was the availability and quality of data. The first predictive model was deployed 6 months after the project kickoff, primarily because of a lack of requisite data. This delay underscored the necessity of performing a comprehensive data-readiness check as part of the project startup phase.
Ensuring the availability of sufficient, accurate, and reliable data is fundamental to meeting project objectives, particularly in AI and ML initiatives. A data-readiness check should include an assessment of data sources, quality, and completeness. It should also include a review of contracts related to equipment. During Murphy’s project, it was discovered that the daily progress reports and event data from CMMS were incomplete and lacked quality in certain aspects because not all maintenance was tracked through the work order system. This gap significantly hindered the ability to develop robust predictive models.
Incorporating a thorough data-readiness check at the project’s inception would involve verifying the integrity of these reports and event data. This process includes evaluating existing data for relevance to the predictive maintenance goals and identifying any gaps that need to be addressed before model development begins. Ensuring data completeness and quality at this stage would have allowed for a more streamlined model-development process and accelerated deployment timelines.
Although the input data were not perfect, the project allowed the team to build a proper workflow and gain insights into what works and what does not. By addressing these data-related challenges proactively, future projects can build on a solid foundation of high-quality data, thereby enhancing the reliability and effectiveness of the predictive models.
Domain Knowledge. Another critical lesson learned was the effect of domain knowledge on project effectiveness. The service partner engaged to develop the AI/ML-based predictive maintenance models lacked sufficient expertise in oil and natural-gas equipment and processes, which hampered the overall efficiency and effectiveness of the project. Moving forward, it is essential to engage service partners with relevant domain knowledge and experience, such as a rotating-equipment specialist. This ensures that the project benefits from specialized insights and best practices intrinsic to the industry. Proper vetting processes and competency evaluations should be instituted to select service partners who can contribute meaningfully to project goals.
By addressing these aspects, projects can be better planned and managed, leading to smoother execution and more successful outcomes.
Model Development, Performance, and User Experience. Another vital aspect of the project was the development of predictive models. Initially, the models created were akin to “check engine” lights, merely signaling the presence of an anomaly without providing detailed specifics or prescriptions for addressing the issue. This limitation meant that, while personnel could detect that something was wrong, they lacked the granularity to identify the precise nature of the failure and potential solutions. Additionally, because of these generic alerts, a significant amount of time was spent investigating the anomalies, which often turned out to be transient behavior of the equipment or false positives.
In hindsight, the models should have been designed to detect specific failure modes of the rotating equipment based on the available data. To achieve this, resources such as ISO 14224 and the Offshore Reliability Data should have been consulted to identify prevalent failure modes of the rotating equipment. These standards provide comprehensive guidelines and data on equipment failures, which would have been invaluable in the development of more targeted and effective predictive models.
Furthermore, a complete evaluation of the available data’s sufficiency in detecting specific failure modes should have been conducted. This would involve running tests to determine if the available data can detect the failure modes of interest or not. This step is critical to ensure that the models are not only accurate but also reliable in diverse operational conditions. By focusing on specific failure modes and leveraging comprehensive industry standards, the predictive models would have provided more actionable insights, thereby enhancing the maintenance strategies and reducing downtime.
Through these refinements in model development, future projects can achieve a higher level of precision in anomaly detection, leading to more effective predictive maintenance solutions.
Future Works
Looking ahead, several key areas have been identified for improvement to enhance the effectiveness and reliability of the predictive maintenance projects.
First, improving the quality of event data in CMMS is paramount. High-quality data is the backbone of any predictive maintenance initiative, and ensuring its accuracy, completeness, and relevance will significantly affect the performance of predictive models. Regular audits and data cleansing should be instituted to maintain the integrity of the event data.
Second, ensuring the appropriate level of instrumentation on equipment of interest is crucial. Adequate and precise instrumentation allows for the collection of detailed operational data, which is necessary for developing accurate and reliable predictive models. Investments in modern sensors and data-acquisition systems should be prioritized to cover all critical aspects of equipment performance. To bring this into real-world applicability, a thorough cost/benefit analysis is essential to determine where such investments would yield the most value. For instance, the decision to retrofit a piece of equipment with a thermowell or install additional sensors must be justified by the criticality of the data it provides and the likelihood of failure it aims to mitigate. The cost of upgrading instrumentation needs to align with the potential consequences of equipment failure, ensuring a measurable return on investment. This approach would allow organizations to allocate their resources effectively while enhancing system reliability and prioritizing efficiency.
Third, developing in-house knowledge of rotating equipment is essential. Building a team with specialized expertise in rotating machinery will enable a deeper understanding of the equipment and its failure modes. This knowledge is invaluable for creating more targeted and effective predictive models. Training programs and knowledge-sharing initiatives should be implemented to foster this expertise within the organization.
Finally, revisiting AI/ML solutions is necessary to keep pace with technological advancements. The landscape of AI/ML is constantly evolving, and staying updated with the latest methodologies and tools will ensure that the predictive maintenance strategies remain cutting-edge. Regularly reviewing and updating AI/ML solutions will help in refining model accuracy and improving predictive capabilities.
By focusing on these areas, projects can leverage enhanced data quality, purposeful instrumentation, domain-specific knowledge, and advanced AI/ML solutions to achieve greater success in predictive maintenance endeavors.