

What Is clustering?
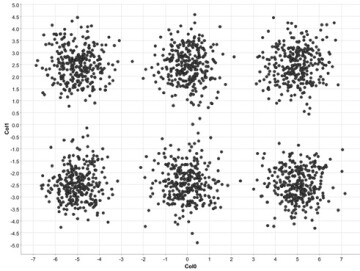
Let's get straight into it and take a look at this scatter plot to explain. As you may notice, data points seem to concentrate into distinct groups (Fig. 1).
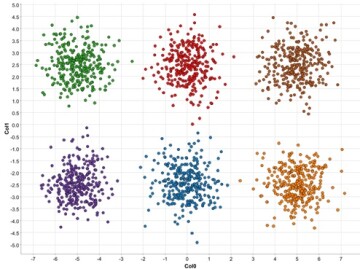
To make this obvious, we show the same data but now data points are colored (Fig. 2). These points concentrate in different groups, or clusters, because their coordinates are close to each other. In this example, spatial coordinates represent two numerical features and their spatial proximity can be interpreted as how similar they are in terms of their features. Realistically speaking, we may have many features in our data set, but the idea of closeness (similarity) still applies even in a higher dimensional space. Moreover, it is not unusual to observe clusters in real data, representing different groups of data points with similar characteristics.
Clustering refers to algorithms to uncover such clusters in unlabeled data. Data points belonging to the same cluster exhibit similar features, whereas data points from different clusters are dissimilar to each other. The identification of such clusters leads to segmentation of data points into a number of distinct groups. Because groups are identified from the data itself, as opposed to known target classes, clustering is considered as unsupervised learning.
As you have seen already, clustering can identify (previously unknown) groups in the data. Relatively homogenous data points belonging to the same cluster can be summarized by a single cluster representative, and this enables data reduction. Clustering can also be used to identify unusual observations distinct from other clusters, such as outliers and noises.

Clusters formed by different clustering methods may have different characteristics (Fig. 3). Clusters may have different shapes, sizes, and densities. Clusters may form a hierarchy (e.g., Cluster C is formed by merging Clusters A and B). Clusters may be disjointed, touching, or overlapping. Now, let us examine how clusters with different properties are produced by different clustering algorithms. In particular, we give an overview of three clustering methods: k-Means clustering, hierarchical clustering, and DBSCAN.