
The oil and gas industry is facing unprecedented and brutal market conditions. While the industry was already in the midst of digitalization, the oil price crash has instilled a fresh impetus on its adoption to cut costs through innovation and new technologies. One such technology is predictive maintenance. When equipment on a rig breaks down, the resulting problem often is not that of replacement but the forced downtime in production or drilling. Therefore, predicting when equipment or a system is going to fail and determining the root cause of failure unlocks significant value.
Predictive maintenance has rapidly gained in popularity, spurred by well publicized advances in high-performing computing and Internet of Things (IoT) technologies. Some companies are experiencing the benefits of predictive maintenance firsthand. For example, engineers at Baker Hughes implemented predictive maintenance on the company’s fleet of fracturing trucks. They collected nearly a terabyte of data from pumps on these trucks and then used signal-processing techniques to identify the relevant sensors. Finally, they applied machine-learning techniques to distinguish a healthy pump from an unhealthy one and reduced overall costs by $10 million (MathWorks 2019). This success story and others like it have made pursuing predictive maintenance projects a priority among both oilfield operators and services firms.
There are, however, two common engineering obstacles to implementation.
- Appropriate failure data is missing. One of the fundamental building blocks that these methods rely on are the pattern recognition capabilities of machine-learning algorithms. These algorithms are trained on historical failure data so that they recognize the warning signs to trigger just-in-time maintenance. While the oil and gas industry faces no dearth of data, this might not be the most appropriate data to train fault-detection models. The reason is that machines have several modes of failure and not all of these might be reflected in the process data. In addition, failure data may not exist if maintenance is performed frequently. Even if you have the failure data for specific equipment, it will not be applicable to the same equipment in different operating conditions.
- Privacy issues. Original equipment manufacturers (OEMs) and services firms looking to deploy predictive maintenance algorithms for a specific customer are often constrained by important privacy and security concerns. Hoarding data and not using them can be a common theme in the oil and gas industry (JPT 2019). There are ways to anonymize datasets, but they are time consuming and often not fully effective. While there have been some encouraging signs that this process might evolve (JPT 2019), access to operators’ data remains a challenge.
To help avoid both of these challenges from becoming fatal deficiencies, reliability and maintenance engineers can use digital twins.
Using Digital Twins To Generate Data
Digital twins are increasingly gaining use for monitoring and optimizing the operation of assets. In the predictive maintenance scenario, digital twins play a strong role in generating data and combining it with available sensor data to build and validate predictive maintenance algorithms.
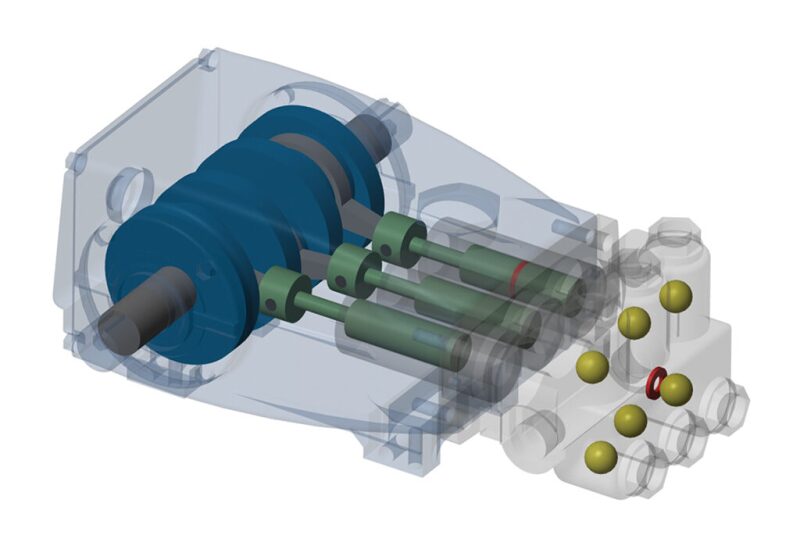
Consider an example of a common type of pump used in both drilling and well service operations—the triplex pump. Most OEMs have the CAD models available. These can be used as a starting point for 3D multibody simulations, which can be imported into dynamic modeling software. If a CAD model is not available, some software also has prebuilt modules to construct the mechanical models. Modeling the dynamic behavior of the system involves complementing the physical model with hydraulic and electrical elements.
Some of the parameters needed for creating a digital twin can be found in the data sheet (bore, stroke, shaft diameter, etc.), but others may be missing or are specified only in terms of ranges. In these cases, engineers need to make an educated estimate.
Simulating the pump with rough estimates, the blue line in the pump outlet pressure chart in Fig. 1 does not sufficiently match the field data, shown by the black line. The blue line resembles the measured curve to some extent, but the differences are obviously large. Optimization is used to fine tune the estimated parameters by reconciling the model output with field data. We now have a digital twin of our pump that reflects our asset in the field; the next step is to obtain from the twin the behavior of failed components.
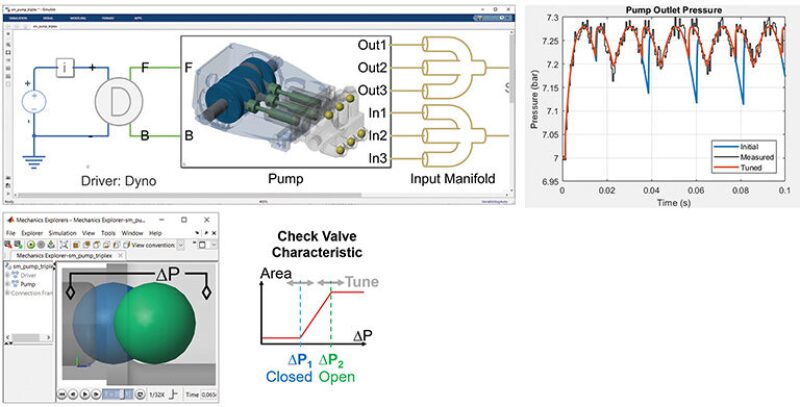
An engineer with system knowledge will be able to generate synthetic failure data with the right tools. Failure-mode-and-effects analysis (FMEA) provides useful starting points for determining which failures to simulate (for example, fatigue, fracture, corrosion, and erosion).
In the case of this pump, simply changing the parameter values can model faults. For example, a worn bearing and a blocked inlet can be simulated by changing parameters such as friction factor and diameter of the tube, respectively. More complicated faults, such as leakage, might require structural changes to the underlying model. Use this knowledge to parameterize the digital twin according to the faults the system is likely to suffer. These faults (and their combinations) can then be simulated. Noise must be included to train the fault-detection algorithm with data that are as realistic as possible (Fig. 2). Once the resulting failure data are labeled and stored for further analysis, it is best to save it so other teams can utilize it and not have to spend resources regenerating it.
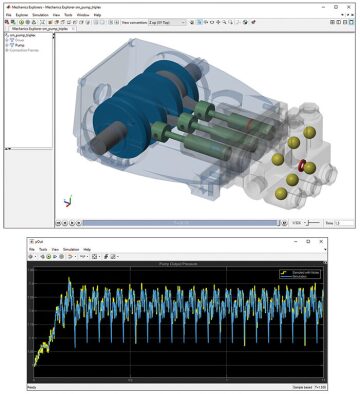
Building, Deploying, and Updating the Model
From this data, meaningful features are extracted and then used to develop a suitable machine-learning model. Once verification is completed, these algorithms can be deployed on real-time data.
A change in the operating conditions affects the sensor measurements, making the fault detection algorithm unreliable. The ability to quickly update the algorithm to account for new conditions is critical for using this equipment in different environments.
An example when this might be useful is for pumps that are used across the world under widely divergent environmental conditions. Such equipment may be subject to change: A new seal or valve supplier may be selected, or the pump may be operated with various kinds of fluids or in new environments with different daily temperature ranges. All these factors affect the sensor measurements, possibly making the fault-detection algorithm unreliable or even useless. The ability to quickly update the algorithm to account for new conditions is critical for using this equipment in new markets.
For cases like these, replicating this process with minimal changes then becomes important for saving time. Ideally, one would like to automate this process with the click of a button. This can be achieved through writing scripts in programming languages. Some software, such as MATLAB, also permits automated script generation, which allows most of the work to be quickly modified and reused. The only step that needs to be repeated is data acquisition under conditions comparable to those the pump will face in the field.
With the latest advances in smart interconnectivity, it will be possible for OEMs to remotely update and redeploy these models to the equipment. The insights gathered on numerous machines will benefit both oilfield operators and service companies.
Summary
Predictive maintenance helps engineers determine exactly when equipment needs maintenance. It reduces downtime and prevents equipment failure by enabling maintenance to be performed based on need rather than a predetermined schedule. Often it is too difficult to create the fault conditions necessary for training a predictive maintenance algorithm on the actual machine. A solution to this challenge is to use a digital twin that has been tuned to reflect the field asset. Simulated failure data are generated, which are then used to design a fault-detection algorithm. The process can be automated, enabling quick adjustment to varying process conditions.
References
Baker Hughes Develops Predictive Maintenance Software for Gas and Oil Extraction Equipment Using Data Analytics and Machine Learning. MathWorks. Accessed 25 November 2019.
Data Is Not Scarce, but Oil Companies Hoard It as if It Were. J Pet Technol. May 2019. Accessed 25 November 2019.
Change in Energy Sector Is So Extreme, Oil Companies May Need To Share Data. J Pet Technol. March 2019. Accessed 25 November 2019.
